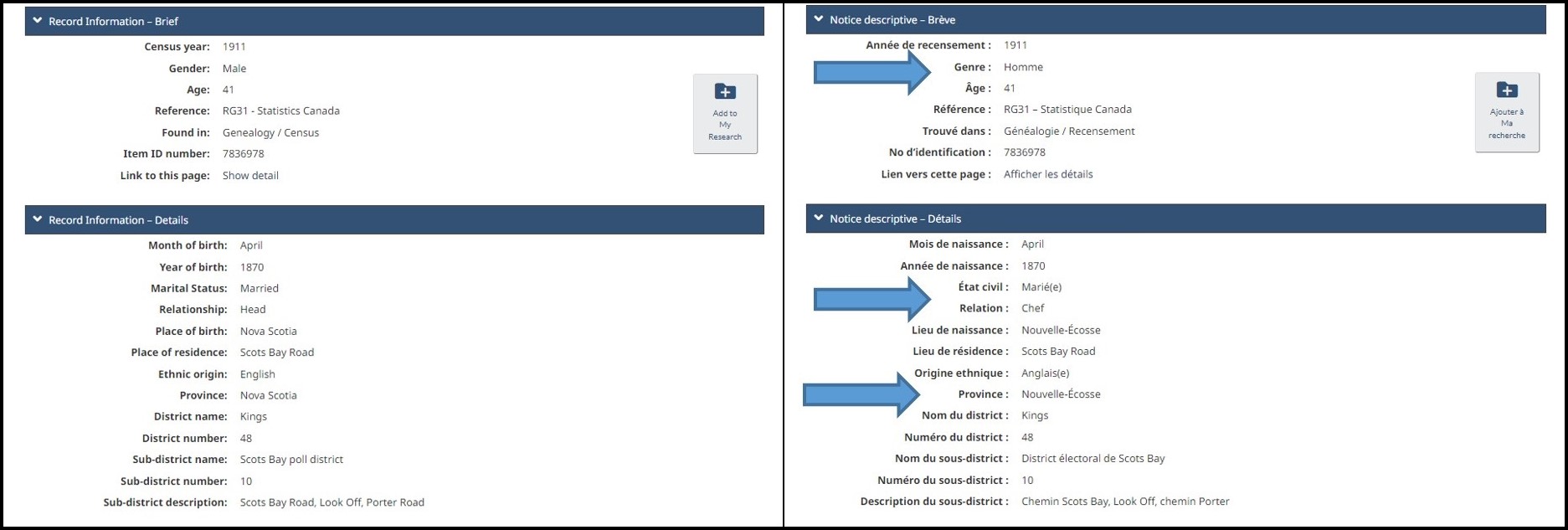
Par James Bone
C’est en juillet 1908 que les inscriptions en français apparaissent sur les timbres-poste canadiens, juste à temps pour l’émission d’une série de timbres soulignant le 300e anniversaire de la fondation de Québec par Samuel de Champlain. Il faut toutefois attendre juin 1927 pour que des timbres-poste bilingues, accordant une place égale au français, soient émis de manière systématique. Ce jalon coïncide avec le lancement d’une série de timbres mettant notamment en vedette les Pères de la Confédération et le nouvel édifice du Centre du Parlement. La traduction relève de l’ancien Bureau des traductions du gouvernement fédéral (aujourd’hui le Bureau de la traduction); le français utilisé ne pose donc pas de problème. Mais tout cela change à la suite d’une erreur commise en 1946, qui débouchera sur le premier timbre-poste canadien contenant une faute d’orthographe.
À l’époque, l’aviation et la poste aérienne sont des innovations relativement récentes, et des timbres sont émis pour les clients qui sont prêts à payer davantage pour ce service. Moyennant des frais supplémentaires, les clients peuvent aussi se prévaloir du service de livraison accélérée. En juillet 1942, on émet un timbre combinant les services de la poste aérienne et la livraison exprès. On peut y voir un avion survolant Drummondville, au Québec. Un autre timbre du genre est émis en septembre 1946, illustrant cette fois le tout nouvel avion Douglas DC-4M survolant les Plaines d’Abraham et le fleuve Saint-Laurent, à Québec. Ce timbre comporte cependant une petite erreur qui marquera l’histoire de la philatélie au Canada.
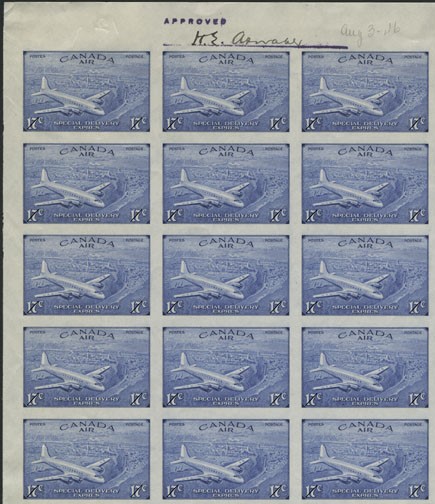
Détail du feuillet de timbres sur le service de livraison aérienne exprès, approuvé malgré une faute d’orthographe. (No MIKAN 2222196)
Toujours à l’époque, les graveurs qui illustrent les timbres travaillent dans une imprimerie (dans ce cas-ci, la Compagnie canadienne des billets de banque limitée, à Ottawa). Ils doivent adapter chaque dessin à un bloc imprimant qui correspond à la taille du timbre. Avant l’impression, les épreuves et un feuillet d’essais sont approuvés par l’imprimeur et par le ministère des Postes.
Le timbre comportant l’erreur est mis en circulation le 16 septembre 1946. Comme l’indiquent les archives du ministère des Postes, à peine deux semaines plus tard, le 1er octobre, le ministre des Postes de l’époque, Ernest Bertrand, reçoit une lettre de J. A. Boissonneault. Ce résident de Québec l’informe que le timbre comporte une erreur : le mot français exprès est gravé avec le mauvais accent (un accent circonflexe au lieu de l’accent grave), ce qui donne l’épellation « exprês ».

Détail de l’épreuve approuvée avec une faute d’orthographe. (No MIKAN 2222194)
La lettre de M. Boissonneault déclenche un branle-bas au bureau du sous-ministre des Postes par intérim, H. E. Atwater. Celui-ci demande au traducteur du timbre, un certain M. Marier du Bureau des traductions, de se pencher sur la question. M. Marier examine un agrandissement de l’épreuve et confirme l’erreur. M. Atwater écrit alors au vice-président de la Compagnie canadienne des billets de banque, P. J. Wood. Il veut savoir comment cette erreur a pu se produire, étant donné que les timbres précédents sur le service de livraison exprès ne comportaient aucune faute.
Dans sa réponse, M. Wood s’excuse de l’erreur commise, mais rappelle que l’épreuve finale a été approuvée à la fois par la Compagnie et par le ministère des Postes; les deux parties sont donc responsables. M. Wood recommande ensuite à M. Atwater de modifier la matrice pour corriger l’erreur, mais le met en garde contre le risque que la modification soit remarquée et rendue publique.
Le 5 octobre, M. Atwater autorise la modification de la matrice, convenant que les collectionneurs de timbres le remarqueront sans doute. Le même jour, une réponse est envoyée à M. Boissonneault pour le remercier d’avoir attiré l’attention sur cette erreur et l’assurer qu’elle sera corrigée.
L’erreur est rendue publique pour la première fois dans un article du Ottawa Journal du 7 octobre 1946. A. Stanley Deaville, surintendant de la division des timbres-poste, y reconnaît avoir été informé de l’erreur; il déclare que les timbres déjà imprimés et mis en vente ne seront pas retirés de la circulation. En effet, les rappeler serait mission impossible : environ 300 000 timbres ont déjà été imprimés. M. Deaville se demande également si la partie gauche de l’accent circonflexe ne ferait pas partie du premier e du mot « Delivery », inscrit juste au-dessus – une hypothèse infirmée par un examen minutieux.
En date du 8 octobre, la Compagnie canadienne des billets de banque a modifié la matrice et soumis une nouvelle épreuve à M. Atwater, qui l’accepte et la retourne le 10 octobre. Les timbres corrigés sont mis en vente le 3 décembre 1946; on en imprimera 900 000 au total.

Détail de l’épreuve approuvée après la correction de l’erreur. (No MIKAN 2222203)
Bibliothèque et Archives Canada a récemment fait l’acquisition de la copie de l’épreuve finale préparée par l’imprimeur et montrant le timbre corrigé. Conservée par la Compagnie canadienne des billets de banque, cette copie confirme la modification apportée.

Copie de l’imprimeur montrant l’épreuve finale corrigée du timbre sur le service de poste aérienne exprès. (No MIKAN 6221976)
La collection philatélique de Bibliothèque et Archives Canada comprend également la copie de l’épreuve finale approuvée par M. Atwater. Fait intéressant à souligner, qui s’explique sans doute par la hâte de corriger l’erreur : la date d’approbation inscrite à la main sur l’épreuve (« 9/9/46 ») est manifestement erronée, en avance d’un mois, car l’épreuve aurait été soumise à l’approbation du ministère des Postes le 9 octobre 1946.

Épreuve finale approuvée du timbre sur le service de poste aérienne exprès. L’orthographe a été corrigée, mais la date est erronée. (No MIKAN 2222203)
Bien que de telles erreurs demeurent rares, d’autres timbres-poste canadiens seront émis avec des fautes d’orthographe. En janvier 2012, dans le cadre de la série « La fierté canadienne », un timbre émis en l’honneur de l’athlète de bobsleigh Pierre Lueders comporte deux fautes. Le nom de l’athlète est incorrectement épelé « Leuders », à la fois dans les petits caractères du timbre et dans le texte de couverture du carnet, des feuillets-souvenirs et des cartes postales prépayées de la série. De plus, dans le marquage – un dispositif de sécurité anti-contrefaçon, visible à la lumière ultraviolette –, le nom Lueders est encore une fois mal orthographié, de même que le mot « Permanent », écrit « Permanant ».
Encore une fois, ces deux erreurs seront corrigées lors des réimpressions subséquentes, mais les timbres fautifs demeureront recherchés par les collectionneurs.
James Bone est archiviste à la Section des archives visuelles et sonores de la Direction générale des archives privées et du patrimoine publié, à Bibliothèque et Archives Canada.